Fast. Accurate. Easy to use. Stata is a complete, integrated software package that provides all your data science needs — data manipulation, visualization, statistics, and automated reporting.

Master your data
Stata’s data management features give you complete control.
- Frames — manage multiple datasets simultaneously
- Import, export
- JDBC, ODBC, SQL
- Sort, match, merge, join, append, create
- Built-in spreadsheet
- Unicode
- Process text or binary data
- Access data locally or on the web
- Collect statistics across groups
- BLOBs—strings that can hold entire documents
- Billions of observations
- Hundreds of thousands of variables
- Survival data, panel data, multilevel data, survey data, discrete choice data, multiple-imputation data, categorical data, time-series data
And much more, to support all your data science needs.
Explore all of Stata’s data management features »

Broad suite of statistical features

Publication-quality graphics

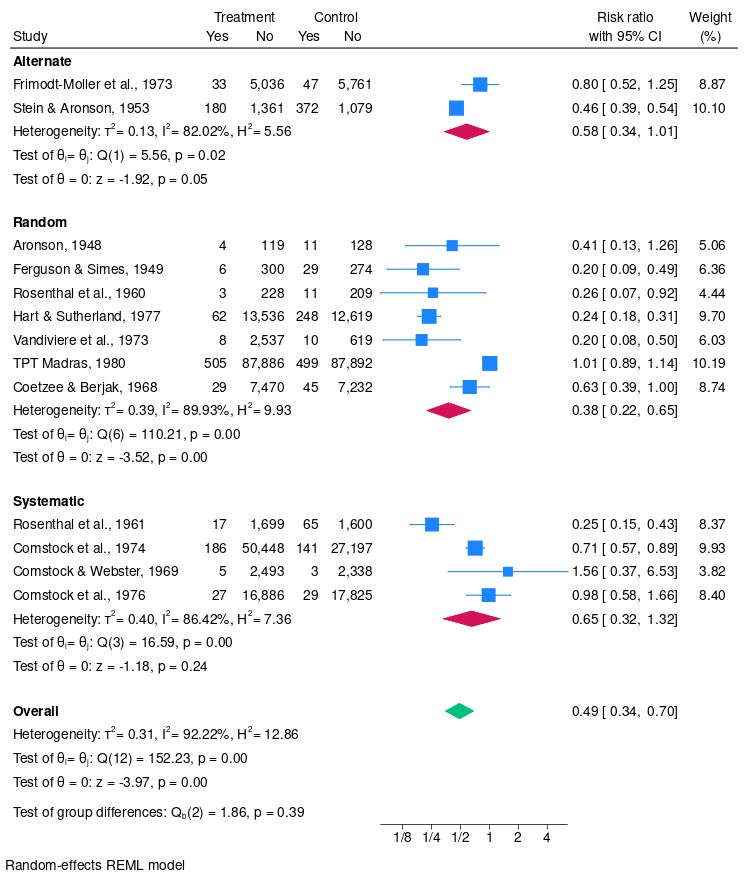




Stata makes it easy to generate publication-quality, distinctly styled graphs.
You can point and click to create a custom graph. Or you can write scripts to produce hundreds or thousands of graphs in a reproducible manner. Use a graphics scheme to produce a graph in the style you want. Export graphs to EPS or TIFF for publication, to PNG or SVG for the web, or to PDF for viewing. With the integrated Graph Editor, you click to change anything about your graph or to add titles, notes, lines, arrows, and text.
Discover Stata’s publication-quality graphics »

Automated reporting
All the tools you need to automate reporting your results.
- Dynamic Markdown documents
- Create Word documents
- Create PDF documents
- Create Excel files
- Customizable tables
- Include publication-quality graphs
- Word, HTML, PDF, Excel, SVG, PNG
Truly reproducible research
Lots of folks talk about reproducible research.
Stata has been dedicated to it for over 40 years.
We constantly add new features; we have even fundamentally changed language elements. No matter. Stata is the only statistical package with integrated versioning. If you wrote a script to perform an analysis in 1985, that same script will still run and still produce the same results today. Any dataset you created in 1985, you can read today. And the same will be true in 2050. Stata will be able to run anything you do today.
We take reproducibility seriously.
PyStata — Python integration
Invoke Python interactively or embed Python in your Stata code.
Invoke Stata from Python and call Stata code from IPython environments.
Use Stata within Jupyter Notebook.
Seamlessly pass data and results between Stata and Python.
Use Stata analyses from within Python.
Use any Python package within Stata
- Matplotlib and seaborn for visualization
- Beautiful Soup and Scrapy for web scraping
- NumPy and pandas for numerical analysis
- TensorFlow and scikit-learn for machine learning
- And much more

Real documentation


When it comes time to perform your analyses or understand the methods you are using, Stata does not leave you high and dry or ordering books to learn every detail.
Each of our data management features is fully explained and documented and shown in practice on real examples. Each estimator is fully documented and includes several examples on real data, with real discussions of how to interpret the results. The examples give you the data so you can work along in Stata and even extend the analyses. We give you a Quick start for every feature, showing some of the most common uses. Want even more detail? Our Methods and formulas sections provide the specifics of what is being computed, and our References point you to even more information.
Stata is a big package and so has lots of documentation – over 19,000 pages in 36 volumes. But don’t worry, type help my topic, and Stata will search its keywords, indexes, and even community-contributed packages to bring you everything you need to know about your topic. Everything is available right within Stata.
Trusted
We don’t just program statistical methods, we validate them.
The results you see from a Stata estimator rest on comparisons with other estimators, Monte Carlo simulations of consistency and coverage, and extensive testing by our statisticians. Every Stata we ship has passed a certification suite that includes 7.2 million lines of testing code that produces 6 million lines of output. We certify every number and piece of text from those 6 million lines of output.
Reliable
For over 40 years, StataCorp has been loyal to its users by expanding the Stata software with new statistical methods and the latest in reporting, data visualization, data management, and the user interface. With our long-standing release history, we are committed to continually providing stable and reliable software to our diverse community of researchers and practitioners.
Continuously Updated
Staying on the most up-to-date version of Stata is now easier than ever.
StataCorp continually develops new features to enhance Stata software, from the latest statistical methods to the best in reporting, data visualization, and the user interface. With StataNow™, you do not have to wait until the next major release to begin using new features. We will release new features as soon as they are ready so that you can take advantage of them right away.
Easy to use
All of Stata’s features can be accessed through menus, dialogs, control panels, a Data Editor, a Variables Manager, a Graph Editor, a Tables Builder, and even an SEM Diagram Builder. You can point and click your way through any analysis.
If you don’t want to write commands and scripts, you don’t have to.
Even when you are pointing and clicking, you can record all your results and later include them in reports. You can even save the commands created by your actions and reproduce your complete analysis later.

Easy to grow with
The consistency goes even deeper. What you learn about data management commands often applies to estimation commands, and vice versa. There is also a full suite of postestimation commands to perform hypothesis tests, form linear and nonlinear combinations, make predictions, form contrasts, and even perform marginal analysis with interaction plots. These commands work the same way after virtually every estimator.
Sequencing commands to read and clean data, then to perform statistical tests and estimation, and finally to report results is at the heart of reproducible research. Stata makes this process accessible to all researchers.
Easy to automate
Everyone has tasks that they do all the time—create a particular kind of variable, produce a particular table, perform a sequence of statistical steps, compute an RMSE, etc. The possibilities are endless. Stata has thousands of built-in procedures, but you may have tasks that are relatively unique or that you want done in a specific way.
If you have written a script to perform your task on a given dataset, it is easy to transform that script into something that can be used on all your datasets, on any set of variables, and on any set of observations.

Easy to extend
Some of the things you automate may be so useful that you want to share them with colleagues or even make them available to all Stata users. That’s also easy. With just a little code, you can turn an automation script into a Stata command. A command that supports standard features that Stata’s official commands support. A command that can be used in the same way official commands are used.

Advanced programming
Stata also includes an advanced programming language—Mata.
Mata has the structures, pointers, and classes that you expect in your programming language and adds direct support for matrix programming.
Though you don’t need to program to use Stata, it is comforting to know that a fast and complete programming language is an integral part of Stata. Mata is both an interactive environment for manipulating matrices and a full development environment that can produce compiled and optimized code. It includes special features for processing panel data, performs operations on real or complex matrices, provides complete support for object-oriented programming, and is fully integrated with every aspect of Stata.
Stata also has comprehensive Python integration, allowing you to harness all the power of Python directly from your Stata code.
Stata even let’s you incorporate C, C++, and Java plugins in your Stata programs via a native API for each language.
Get the most out of your multicore computer.
No other statistical software comes close.
Enjoy the new features of Stata 19 at top speed.
Community-contributed features
Stata is so programmable that developers and users add new features every day to respond to the growing demands of today’s researchers.
With Stata’s Internet capabilities, new features and official updates can be installed over the Internet with a single click.
World-class technical support
Stata technical support is free to registered users of the current release (Stata 19)
We have a dedicated staff of expert Stata programmers and statisticians to answer your technical questions. From tricky data management solutions to getting your graph looking just right and from explaining a robust standard error to specifying your multilevel model, we have your answers.
See what our customers are saying about our technical support »
Cross-platform compatible
Stata will run on Windows, Mac, and Linux/Unix computers; however, our licenses are not platform specific.
That means if you have a Mac laptop and a Windows desktop, you don’t need two separate licenses to run Stata. You can install your Stata license on any of the supported platforms. Stata datasets, programs, and other data can be shared across platforms without translation. You can also quickly and easily import datasets from other statistical packages, spreadsheets, and databases.
Widely used
Used by researchers for more than 40 years, Stata provides everything you need for data science—data manipulation, visualization, statistics, and automated reporting.
Select your discipline and see how Stata can work for you.
Bio statistics
Data Science
Economics
Education
Epidemiology
Finance, business, and marketing
Institutional Research
Medicine
Political science
Public health
Public policy
Sociology
Can’t find your discipline? See who else is using Stata »
Comprehensive resources
Video tutorials
Stata’s YouTube channel is the perfect resource for new users to Stata, users wanting to learn a new feature in Stata, and professors looking for aids in teaching with Stata. We have over 350 videos on our YouTube channel that have been viewed over 15 million times by Stata users wanting to learn how to label variables, merge datasets, create scatterplots, fit regression models, work with time-series or panel data, fit multilevel models, analyze survival data, perform Bayesian analysis, and use many other features of Stata. View the complete list of videos.
Stata Blog
We write the official Stata Blog, Not Elsewhere Classified (NEC), to share things we think you will find instructive, informative, or just plain entertaining. We have written about how to interpret statistical results; export results into Word, Excel, and LaTeX; perform Monte Carlo simulations; program your own estimators; and more. We also post service and product announcements. Individually signed, the articles in NEC are written by the same people who develop and support Stata.
Free Stata webinars
Stata webinars offer something for everyone. Those new to Stata will get a head start when they join our Ready. Set. Go Stata webinar. Ask questions in the live offering, or get started now by watching this tutorial yourself. Both new and experienced users will want to join our Tips and Tricks webinar and our one-hour feature webinars; each one provides an in-depth look at one of Stata’s statistical, graphical, data management, or reporting features.
Training
A multitude of training options are available to become proficient at Stata quickly. Stata provides hands-on classroom and web-based training courses, customized on-site training courses, and online training through NetCourses, webinars, and video tutorials.
Stata Press
Stata Press® publishes books, manuals, and journals about Stata and general statistics topics for professional researchers of all disciplines. Stata Press® publications, along with books recommended by StataCorp, can be found in the Stata Bookstore.
Stata News
The Stata News is a free publication with columns such as the popular In the Spotlight, where Stata developers give insight into specific Stata features, and the Community corner, where we share unique, helpful, and fun contributions from the user community. The News also contains announcements such as new releases and updates, training schedules, new books, Conferences, and Users Group meetings.
Stata Journal
The Stata Journal is a quarterly publication containing articles about statistics, data analysis, teaching methods, and effective use of Stata’s language. The Journal publishes reviewed papers together with shorter notes and comments, regular columns, book reviews, and other materials of interest to researchers applying statistics in a variety of disciplines.
Vibrant community
Stata Conferences
Whether you are a beginner or an expert, you will find something just for you at Stata conferences, which are held each year in various locations around the world. These meetings showcase in-depth presentations from StataCorp experts and experienced Stata users that focus on helping you use Stata more effectively.
Statalist
A great resource for users is Statalist, a forum where more than 60,000 Stata users exchange thousands of postings and responses each month. Statalist is run and moderated by Stata users and maintained by StataCorp.
User comments
Our users love to share how great Stata is, so we’d like to show you! When we receive nice comments about Stata, we post them here. If you think Stata is great too, send us an email with your comment, and we may share it with the Stata community.
Affordable
Stata is not sold in modules, which means you get everything in one package!
Stata offers several purchase options to fit your budget. You can choose an annual license to ensure you always have access to the latest features, or you can choose a perpetual license. Contact a sales representative or browse our products to find out more about our affordable options.